コラム:Quantum Circuit Learningを用いた分類
5.2節で学んだ Quantum Circuit Learning (量子回路学習、QCL)は機械学習への応用を念頭に設計された量子アルゴリズムである。
5.2節では入出力ともに1次元の関数を扱ったが、現実の機械学習に応用するためには、より複雑な関数を近似できることが必要である。
ここではQCLの機械学習への応用例として、代表的な機械学習のデータセットの一つであるIrisデータセット(Fisherのあやめ)の分類を行う。関数の詳細はこのノートブックと同じフォルダに入っているqcl_prediction.pyにある。
※ このコラムでは、scikit-learn, pandasを使用する。
[1]:
from qcl_classification import QclClassification
[2]:
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
データの概要
まず、scikit-learnから、Irisデータセットを読み込む。
[3]:
# Irisデータセットの読み込み
import pandas as pd
from sklearn import datasets
iris = datasets.load_iris()
# 扱いやすいよう、pandasのDataFrame形式に変換
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target
df['target_names'] = iris.target_names[iris.target]
df.head()
[3]:
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target | target_names | |
|---|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0 | setosa |
ここで、列名の最初の4つ(sepal lengthなど)は、「がく」や花びらの長さ・幅を表しており、target, target_namesはそれぞれ品種番号(0,1,2)、品種名を表している。
[4]:
# サンプル総数
print(f"# of records: {len(df)}\n")
# 各品種のサンプル数
print("value_counts:")
print(df.target_names.value_counts())
# of records: 150
value_counts:
versicolor 50
setosa 50
virginica 50
Name: target_names, dtype: int64
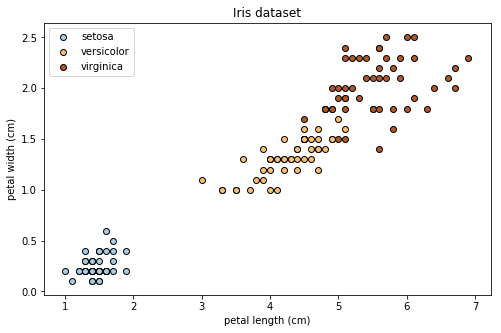
各サンプルについて、sepal length(がくの長さ)など4種類のデータがあるが、これらのうちpetal length(花びらの長さ), petal width(花びらの幅)に着目して分析を行う。
[5]:
## 教師データ作成
# ここではpetal length, petal widthの2種類のデータを用いる。より高次元への拡張は容易である。
x_train = df.loc[:,['petal length (cm)', 'petal width (cm)']].to_numpy() # shape:(150, 2)
y_train = np.eye(3)[iris.target] # one-hot 表現 shape:(150, 3)
[6]:
# データ点のプロット
plt.figure(figsize=(8, 5))
for t in range(3):
x = x_train[iris.target==t][:,0]
y = x_train[iris.target==t][:,1]
cm = [plt.cm.Paired([c]) for c in [0,6,11]]
plt.scatter(x, y, c=cm[t], edgecolors='k', label=iris.target_names[t])
# label
plt.title('Iris dataset')
plt.xlabel('petal length (cm)')
plt.ylabel('petal width (cm)')
plt.legend()
plt.show()
QCLを用いた分類
以下ではQCLを用いた分類問題を解くクラスであるQclClassificationを用いて、実際にIrisデータセットが分類される様子を見る。
[7]:
# 乱数発生器の初期化(量子回路のパラメータの初期値に用いる)
random_seed = 0
np.random.seed(random_seed)
[8]:
# 量子回路のパラメータ
nqubit = 3 ## qubitの数。必要とする出力の次元数よりも多い必要がある
c_depth = 2 ## circuitの深さ
num_class = 3 ## 分類数(ここでは3つの品種に分類)
[9]:
# QclClassificationクラスをインスタンス化
qcl = QclClassification(nqubit, c_depth, num_class)
QclClassificationのfit()メソッドで、関数のfittingを行う。
学習には筆者のPC(CPU:2.3GHz Intel Core i5)で20秒程度を要する。
[10]:
# 最適化手法BFGS法を用いて学習を行う
import time
start = time.time()
res, theta_init, theta_opt = qcl.fit(x_train, y_train, maxiter=10)
print(f'elapsed time: {time.time() - start:.1f}s')
Initial parameter:
[2.74944154 5.60317502 6.0548717 2.40923412 4.97455513 3.32314479
3.56912924 5.8156952 0.44633272 0.54744954 0.12703594 5.23150478
4.88930306 5.46644755 6.14884039 5.02126135 2.89956035 4.90420945]
Initial value of cost function: 0.9218
============================================================
Iteration count...
Iteration: 1 / 10, Value of cost_func: 0.8144
Iteration: 2 / 10, Value of cost_func: 0.7963
Iteration: 3 / 10, Value of cost_func: 0.7910
Iteration: 4 / 10, Value of cost_func: 0.7852
Iteration: 5 / 10, Value of cost_func: 0.7813
Iteration: 6 / 10, Value of cost_func: 0.7651
Iteration: 7 / 10, Value of cost_func: 0.7625
Iteration: 8 / 10, Value of cost_func: 0.7610
Iteration: 9 / 10, Value of cost_func: 0.7574
Iteration: 10 / 10, Value of cost_func: 0.7540
============================================================
Optimized parameter:
[ 2.86824917 6.24554315 5.32897857 1.98106103 4.56865599 3.43562639
3.42852657 5.05621041 0.65309871 1.32475316 -0.62232819 5.72359395
4.27144455 5.69505507 5.8268154 5.44168286 2.90543743 4.74716602]
Final value of cost function: 0.7540
elapsed time: 17.3s
プロット
[11]:
# グラフ用の設定
h = .05 # step size in the mesh
X = x_train
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
[12]:
# 各petal length, petal widthについて、モデルの予測値をプロットする関数
def decision_boundary(X, y, theta, title='(title here)'):
plt.figure(figsize=(8, 5))
# Plot the decision boundary. For that, we will assign a color to each
# point in the mesh [x_min, x_max]x[y_min, y_max].
qcl.set_input_state(np.c_[xx.ravel(), yy.ravel()])
Z = qcl.pred(theta) # モデルのパラメータθも更新される
Z = np.argmax(Z, axis=1)
# Put the result into a color plot
Z = Z.reshape(xx.shape)
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired)
# Plot also the training points
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', cmap=plt.cm.Paired)
# label
plt.title(title)
plt.xlabel('petal length (cm)')
plt.ylabel('petal width (cm)')
plt.show()
[13]:
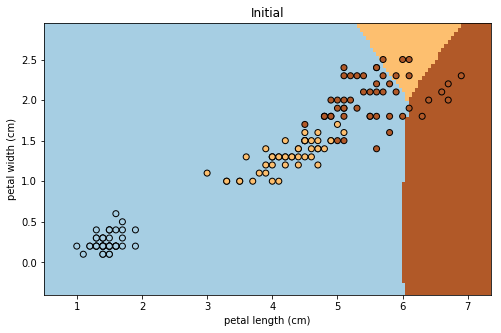
# パラメータthetaの初期値のもとでのグラフ
decision_boundary(x_train, iris.target, theta_init, title='Initial')
[14]:
# パラメータthetaの最適解のもとでのグラフ
decision_boundary(x_train, iris.target, theta_opt, title='Optimized')
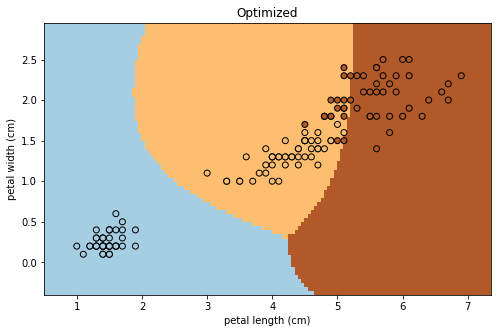
上図、下図がそれぞれ学習前、学習後に対応している。ここで、データ点と各メッシュの色は、それぞれ同じ品種に対応している。
確かにIrisデータセットの分類に成功していることがわかる。
まとめ
本節では、量子回路学習(QCL)を用いて実際の機械学習の問題(分類問題)の解決を行った。
以上は簡単な例ではあるが、量子コンピュータの機械学習への応用の可能性を示唆している。
意欲のある読者は、QCLを用いてより高度な機械学習のタスク(画像認識、自然言語処理など)や、上記モデルの改善に挑戦されたい。
また、更に深く勉強されたい向きは、株式会社QunaSys 御手洗による、量子機械学習に関する講義ノートを参照されたい。